Build Log: Infrastructure Evolution
This log documents the commission of not only a webserver but a HAProxy HA load balancer to simulate real world environments.This is not meant to be an exhaustive how-to, but a proof of work and lab exercise for me personally. As such, only a bare-bones outline of my lab has been created.
1. Infrastructure Provisioning
First, I initialized deployment of an e2-micro instance on Google Cloud Platform running Ubuntu 22.04 LTS.
2. Firewall & Networking
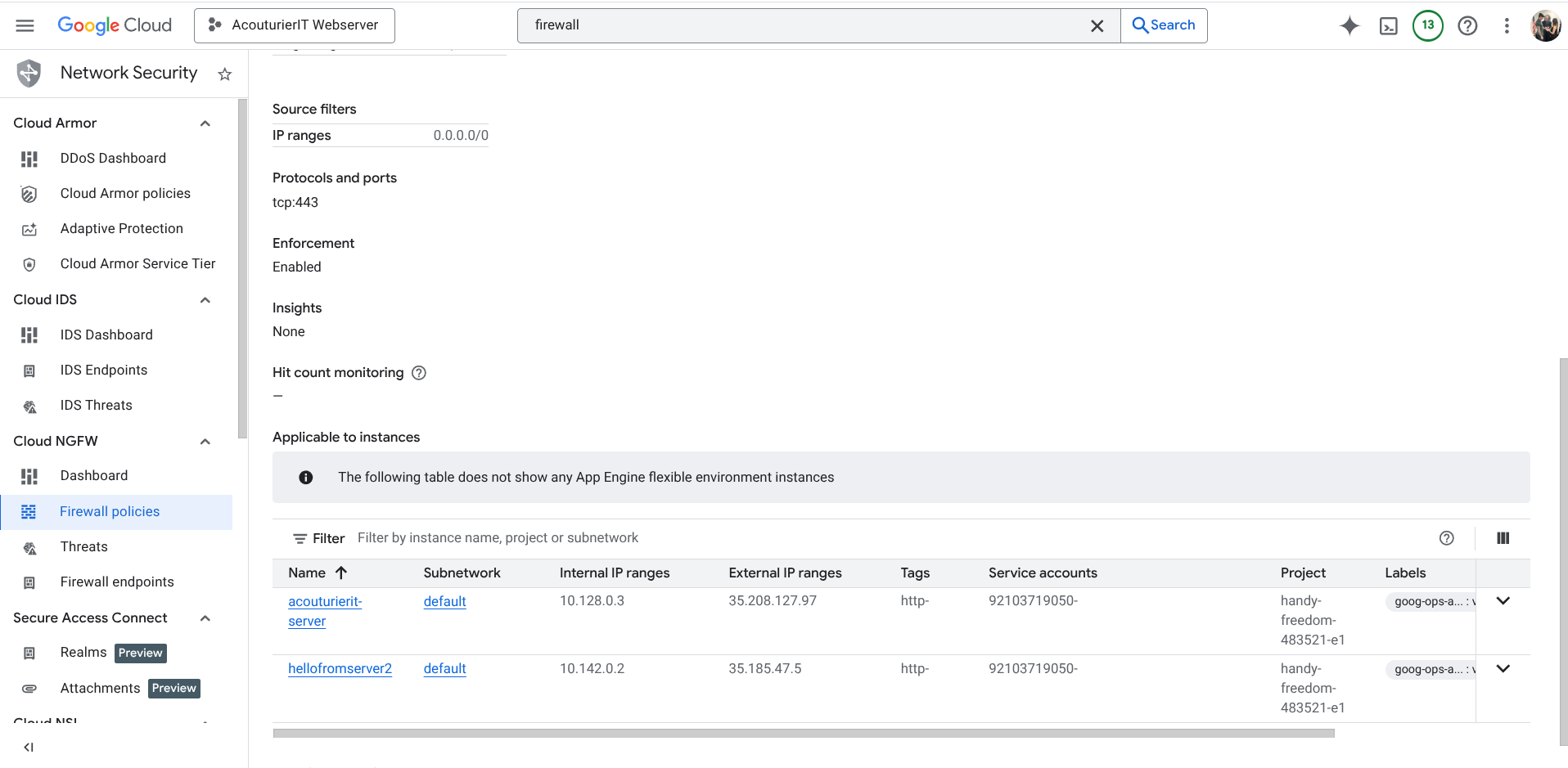
The, I configured the VPC firewall rules to secure ingress traffic on Port 80 and 443.
3. DNS Configuration
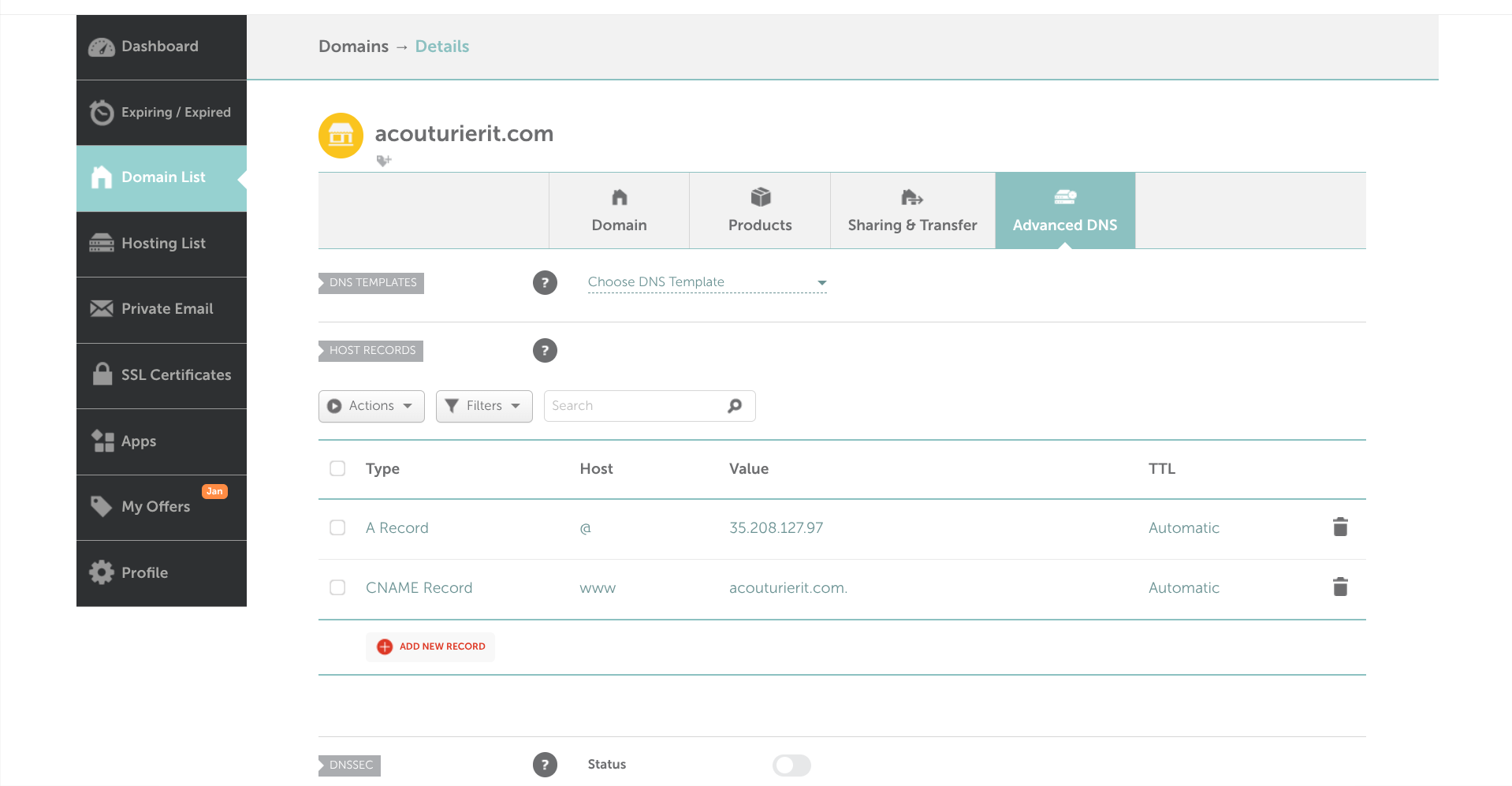
Here I implemented DNS A records via Namecheap to map the AcouturierIT domain to GCP infrastructure.
4. Horizontal Scaling (The Lab Phase)
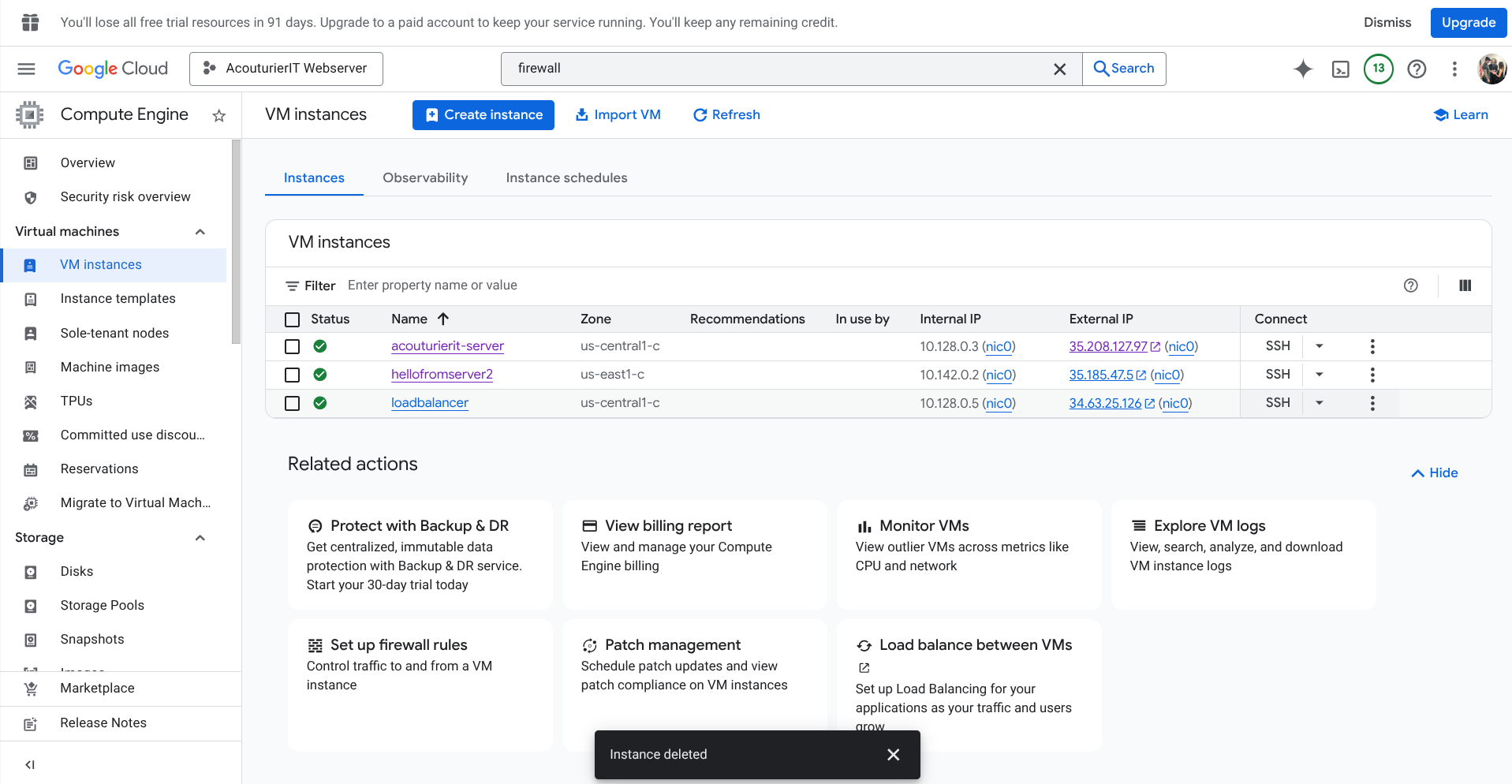
A secondary node was provisioned and synchronized using rsync to eliminate a single point of failure.
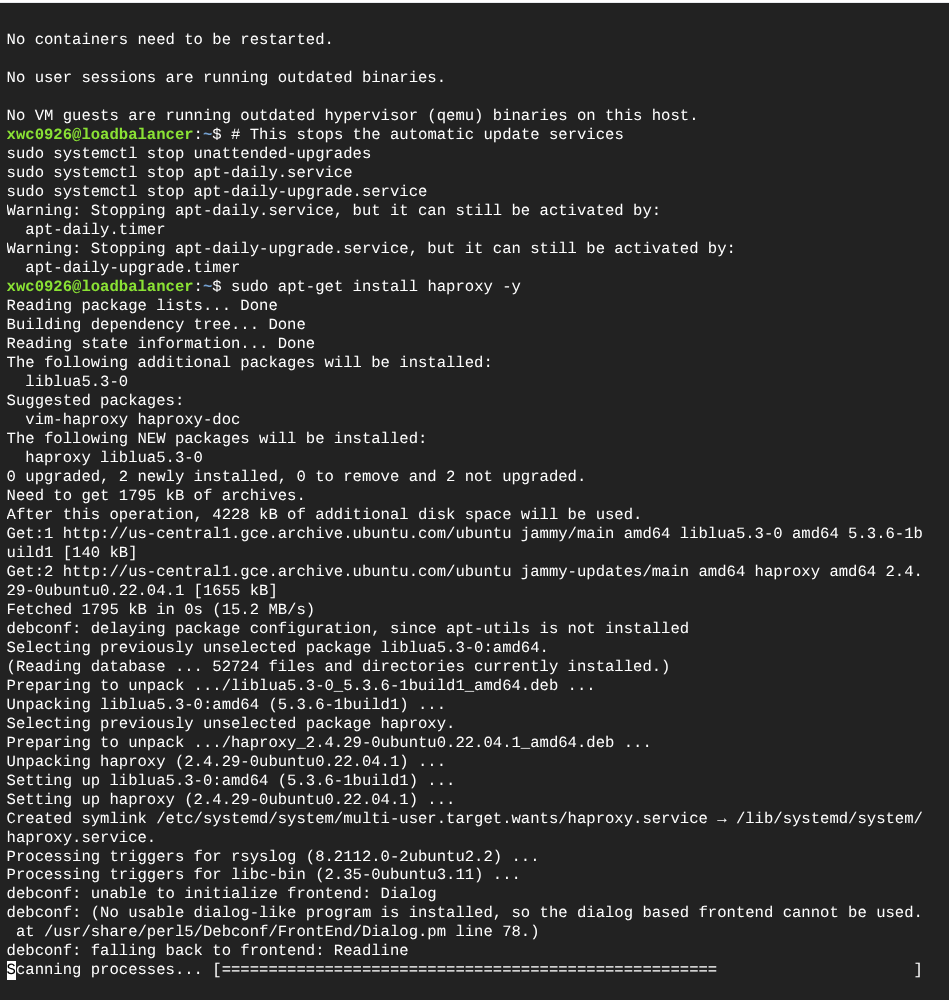
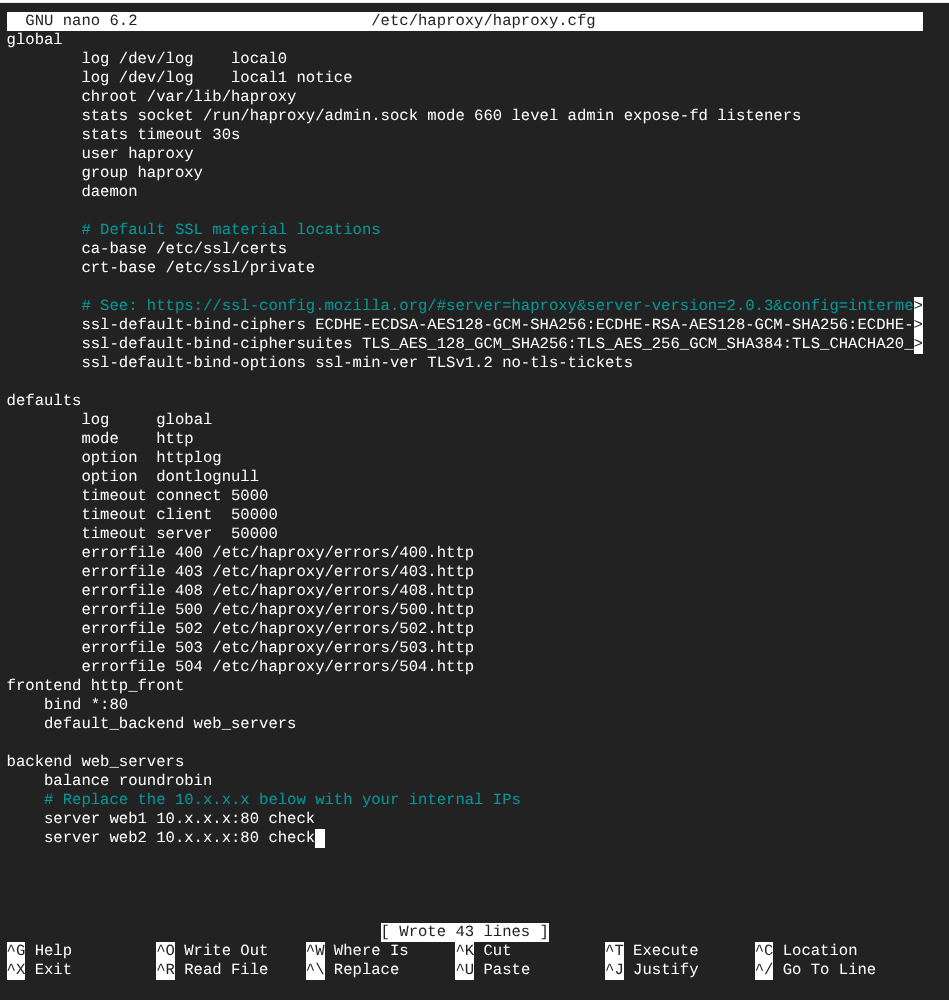
5. Load Balancing (HAProxy)
A dedicated Load Balancer was deployed using HAProxy to manage traffic distribution between healthy nodes via RoundRobin.
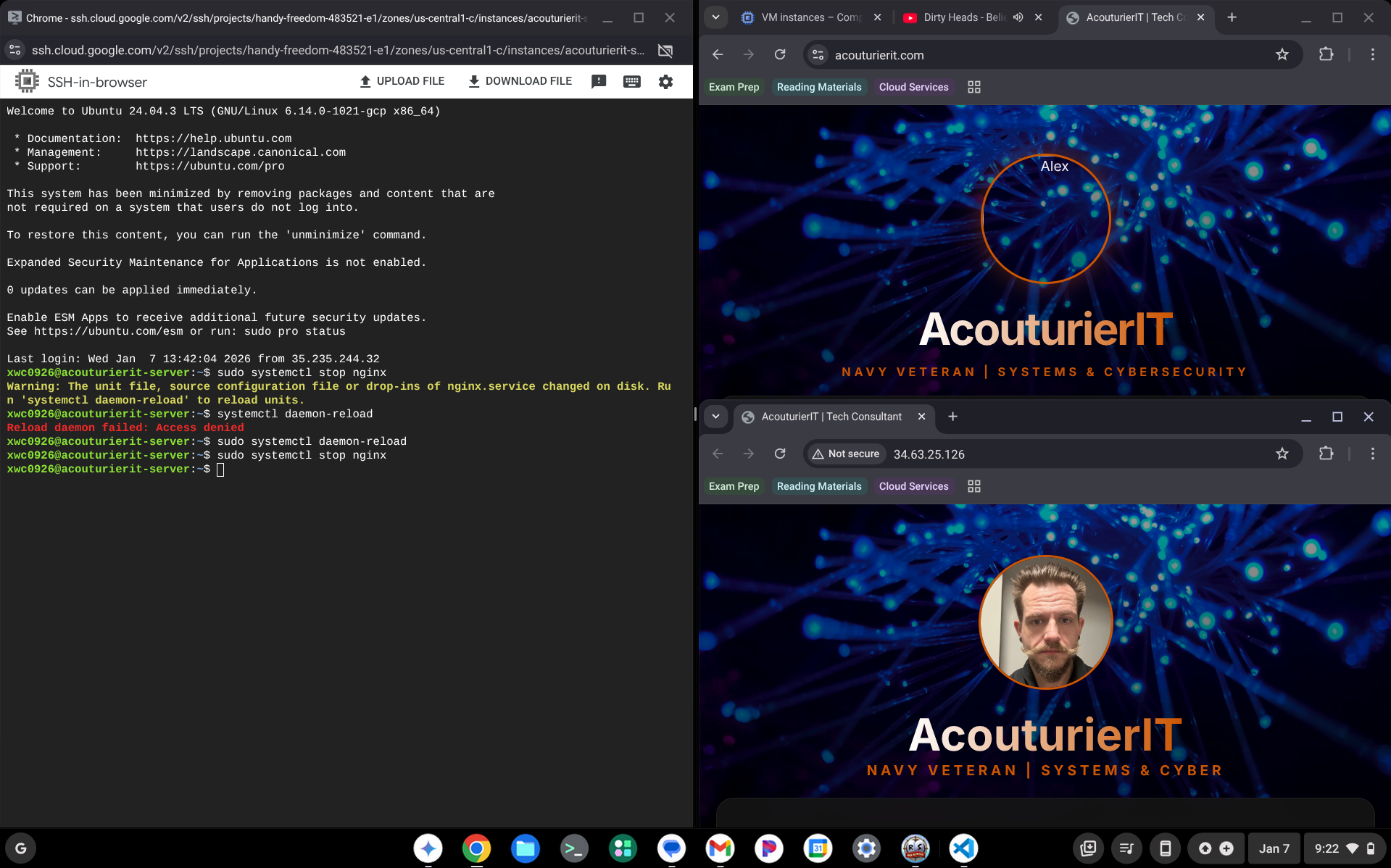
6. Resilience & Kill-Test Results
Simulated a primary server crash to verify automatic failover. The High-Availability architecture maintained 100% uptime by rerouting traffic to the redundant node instantly. Of note is my profile picture not loading, I did not catch this correctly when completing the lab before deleting my instances. To fix this I would ensure file location of all images on server 2.
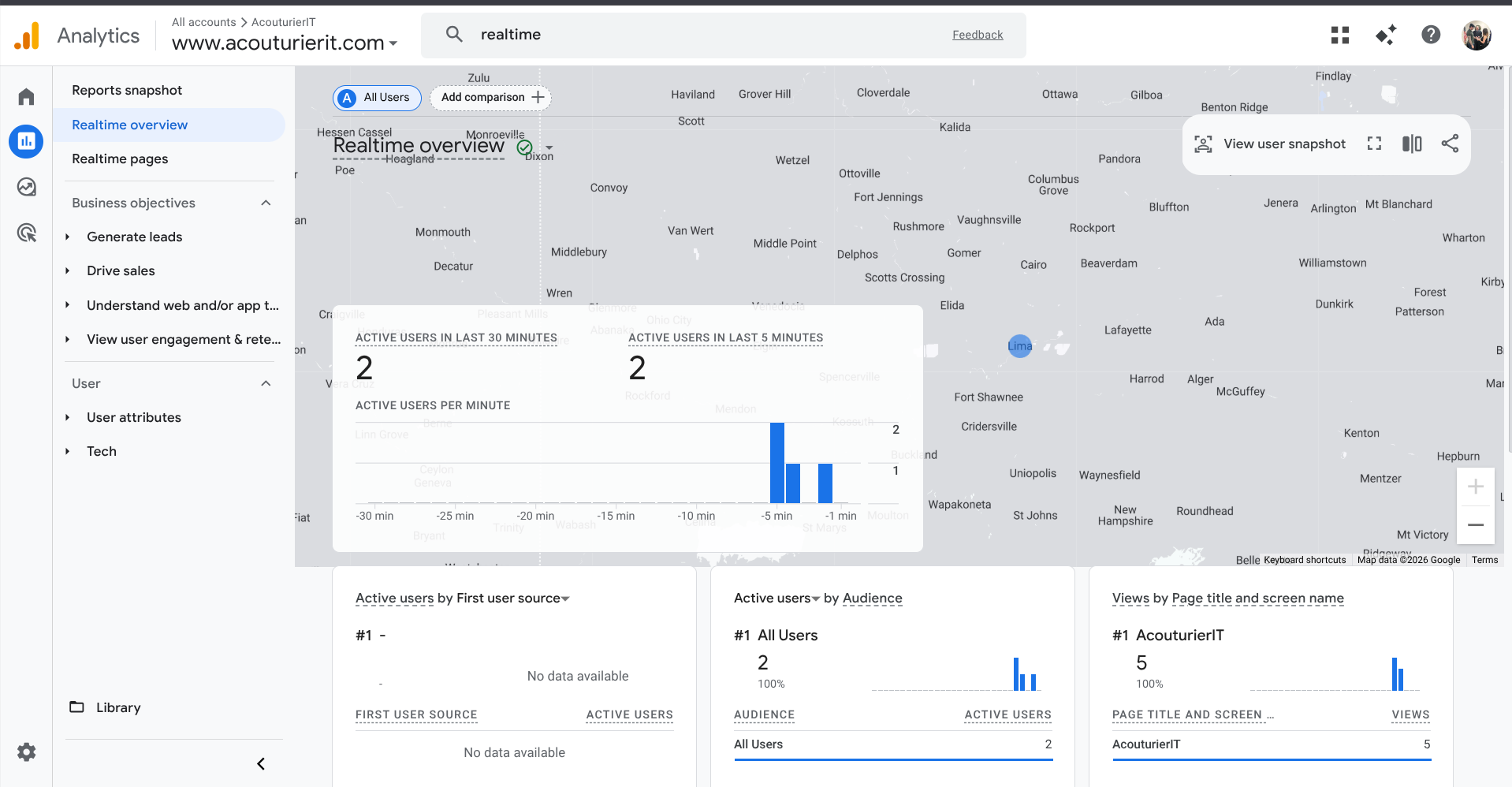
7. Google Analytics
The last step is adding a simple code provided by GA4 to our html coding for the webpages to provide us with tracking so we can see just the amount of engagement we have. This way we know if anyone actually cares about this section!
Technical Conclusion
The High-Availability lab successfully demonstrated zero-downtime architecture and automated synchronization. Following the successful verification of Step 6, the cluster was decommissioned and traffic was rerouted back to a single primary instance to minimize operational costs while maintaining the technical framework for future scaling.